Threats in the architecture phase¶
In the previous chapter, what we needed to find threats was creativity and a clear picture of what we want and do not want the software to do. We may have thought of some mitigations already, and we are now ready to shape them in our design.
Unfortunately, that does not mean that we are protected against all threats. Even if we managed to get our security requirements complete with the help of the previous chapter, every technology that we use, inherently brings threats. If we are not aware of these threats, we risk becoming vulnerable to them. We can mitigate most of these threats by using the technology in a specific way, but sometimes we need to change the architecture or even the functionality of the system.
For example, suppose that we have chosen to implement user authentication by means of a four digit code. We know that this is weak, but our specific user group cannot remember a more difficult authentication code. Because we use password authentication, we face the threat that someone can guess the password. The mitigation of enforcing difficult to guess passwords is not an option here, so we decide to implement two factor authentication by using a hardware token in addition. This will change the user interface of the system.
As another example, say that the package management software that we write needs to unpack an archive that was downloaded from an untrusted source. The threat is that an attacker presents us an archive that will install malicious software onto our machine. Therefore we want to check the integrity via digital signatures. This however requires the configuration of the correct cryptographic keys and a digital signature check. Both user interface and architecture will change.
Every new mitigation can bring new threats, and every change to functionality may raise new security requirements. Even if you do not change any of these, the discovery of new threats can force you to review your functionality and design. Finding threats is an iterative process that will continue after the requirements and architecture phases of your SDLC.
Finding an appropriate mitigation is often a matter of balancing requirements and weighing costs and benefits. This can make it challenging and sometimes a perfect solution is impossible.
Many of the architectural threats however remain present despite having a simple mitigation. Lack of knowledge and not investing time to find such threats are the most common reasons. A systematic way to analyze threats can help.
To find architectural threats, we need an architectural description (usually a diagram), and a threat library. We call the process of finding architectural threats architectural risk analysis or threat modelling 1. The method described here is certainly not the only way to threat model, so feel free to explore other methods.
Architectural description¶
Before we can analyze an architecture, we need to have a clear overview of what it is. Therefore, a complete and correct description of the architecture is essential.
Diagrams¶
One can describe an architecture in many ways. Diagrams are a nice way to do this, since it visually shows how architectural components interact.
A network diagram describes the network infrastructure of a system: which networks exist, which machines connect to them and which components protect those machines from unauthorized access?
To describe how we split up applications into components that communicate with each other, we use a data flow diagram: what type of information do the components send to each other, what protocols do they use, and where and how is data stored?
Communication protocols require yet another way: a sequence diagram, in which we can see the order of messages the parties send.
Despite the fact that we are talking about communication between components, these three ways of describing the communication are very different. What form is most appropriate? That answer depends on the type of threats that we try to detect. The most common form that we encounter in the security literature about threat modelling is the data flow diagram (DFD). Other methods exist, and you are free to choose any method, as long as it works.
Data flow diagrams¶
In a DFD, we use a process to describe something that actively processes information, a data store for something that stores data, but does not do anything with that data. External entities are elements that are outside of the system that we are building. In between these elements, data flows indicate how one element sends data to another element. See figure 1 for an example.
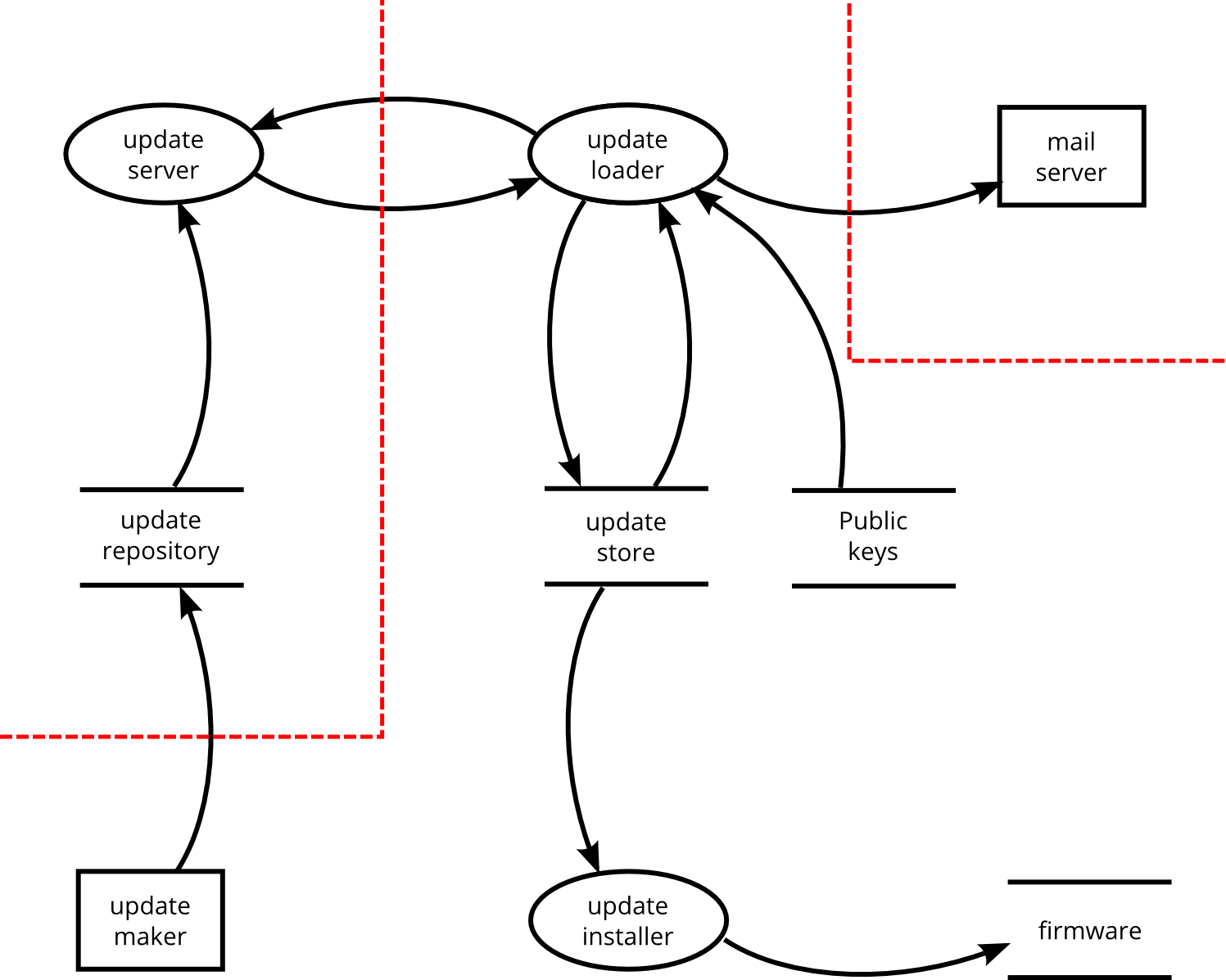
Figure 1: DFD example with trust boundaries.¶
One question that you will encounter is the level of detail of the diagrams. For example, should we list only services that listen on network ports, or also the processes or threads that comprise them? It all depends on the specific threats that we are looking at. You may even need multiple diagrams at different abstraction levels.
Trust zones and trust boundaries¶
The diagram should also tell us where attackers can attack, in other words, it should show the attack surface. In a DFD, we usually divide the diagram into trust zones, separated by trust boundaries. Where to put trust boundaries is often a matter of choice or decision, and not a hard science.
Since there are many types of attack, there are also different trust boundaries. The trust boundary between a process and an attacker on the same machine is a different one from the boundary between the process and an attacker that attacks via the network. This is again different from an attacker that attacks an application via someone’s web browser. We cannot always draw all trust boundaries in the same diagram, but fortunately, we can leave some boundaries implicit, without missing any threats.
Checking your diagram¶
It is often difficult to get your diagram complete. If you try to explain the system’s functionality with the diagram, you will quickly discover if you have missed any elements.
Shostack mentions a few sanity checks for DFD’s [Shostack]. We list a few of them:
a data store with only incoming flows: if data is stored but never read, what is the point of storing it?
a data store with only outgoing flows: data is not magically generated by a data store.
data stores communicating without a process: data stores are passive and cannot initiate data flows by themselves.
a process should have at least one incoming and one outgoing data flow.
Checking whether all trust boundaries are defined is more tricky. A security measure without a corresponding trust boundary reveals either a forgotten trust boundary, or a pointless security measure.
Analyzing the architecture¶
When the architecture is clear, we can check what threats to expect.
Knowing the technologies¶
Since every technology comes with its own threats, it is essential to know what technologies the architecture uses:
processes (web server, SOAP server, Linux ELF executable, …);
data stores (SQL, noSQL, file based);
communication protocols (network or local socket, HTTP, UDP, …);
type of information (personal information, sensitive information, tokens, …).
Annotating the diagram with this information is a good idea, but be careful to keep the diagram readable and avoid too many annotations.
Structure of a threat library¶
A good threat library describes what threats to expect for a certain technology. Every threat should contain at least the following elements:
- Name:
something to refer to this threat.
- Applicable situation:
where and when to expect this threat.
- Description:
what the threat is and how it manifests itself.
- Impact:
what would happen when the threat manifests itself.
- Suggested mitigation:
a possible way to reduce the impact or likelihood of this threat.
To use a very famous threat as an example, we would describe SQL injection as follows:
- Name:
SQL injection
- Applicable situation:
SQL database
- Description:
Data in untrusted input can contain SQL metacharacters and part of SQL commands. These metacharacters and SQL commands are interpreted and executed by the SQL database.
- Impact:
An attacker can execute different SQL commands than intended. This can compromise confidentiality, integrity and availability. If the database is used for authorization, authentication or non-repudiation, these properties can no longer be guaranteed.
- Suggested mitigation:
Use parameterized queries for your SQL statements. If that is not possible, input validation and escaping are second best strategies.
Optional fields that may be useful are:
- Suggested Verification:
how to verify if the threat is mitigated.
- Remarks:
points that require special attention, e.g. implementation pitfalls, special circumstances that require a different mitigation, etc.
- References:
where to find more information, or the source on which this threat is based.
Finding a good threat library¶
At this time of writing, there is hardly any threat information available in a form that we can directly use as a threat library. Therefore, we will have to compile our own threat library from various sources. Fortunately, some work has already been done:
CAPEC and CWE are taxonomies of attack patterns and software weaknesses, respectively. They explain every attack or weakness in sufficient detail. In case you find the structure of the patterns a bit awkward, CAPEC and CWE offer multiple views on their elements [CAPEC] [CWE].
For web applications, OWASP’s Application Security Verification Standard (ASVS) is a rich collection of mitigations that you have to consider to get your web application secure [ASVS]. The downside is that it tells you no background information about why you would need a particular mitigation, which makes it hard to decide whether you need to implement a particular mitigation or search for an alternative mitigation.
For mobile applications, the OWASP Mobile Application Security Verification Standard (MASVS) exists [MASVS]. As you can expect, this is similar to the ASVS.
The IETF requires that all RFCs have a “Security Considerations” section. There is even an RFC on how to write them [RFC3552]. Sometimes a whole RFC exists to document a particular threat model, such as for DNS/DNSSEC [RFC3833], BGP [RFC7132] or OAuth 2.0 [RFC6819].
Other technologies may require some searching. Some threats can be very well hidden in a PhD thesis somewhere and it may take some time and effort to find these. Always keep in mind that the list of threats in your library may be incomplete. Whenever you find a new threat, add it to your threat library.
Other approaches¶
Using a threat library to find architectural threats is not the only way to threat model. Adam Shostack describes a variety of threat modelling techniques in “Threat Modeling, designing for security” [Shostack].
Cheung discusses several threat modeling techniques, including the use of different diagrams, such as Petri nets and UML activity diagrams [Cheung].
Combining several approaches can yield more threats, although there will be some overlap. Using a structured approach such as a threat library can free up your mental resources to think about more creative threats.
Worth mentioning are the STRIDE per element and STRIDE per interaction methods (see [Shostack]). We can view these STRIDE based approaches as a very abstract threat library. A more detailed refinement usually comes from attack trees, of which Shostack gives examples, calling them “threat trees” [Shostack].
A specific threat library or attack tree may not be available for a specific situation. In that case, you will need more security research for that situation. STRIDE can give a good start.
Summary¶
Finding architectural threats goes by names such as architectural risk analysis or threat modelling. Architectural threats are technology specific. We must know what technologies our architecture uses. We express this in an architecture description, usually a diagram. Most threat modelling literature mentions the data flow diagram (DFD). Trust zones and trust boundaries indicate from where an attacker can strike, showing the attack surface.
A threat library helps to find very concrete technology specific threats. Although much information about technology specific security problems is available, very little of it is immediately usable as a threat library. A good threat library explains the threat, the applicable situation, the impact and a suggested mitigation.
More abstract approaches, based on STRIDE, can help in situations in which concrete threats are not (yet) known.
Footnotes
- 1
In “Software Security”, Gary McGraw criticizes the term “threat modelling” for analyzing an architecture. According to McGraw, threats are the attackers themselves [McGraw]. In this document, we use a different definition of threat, i.e. a potential attack, ignoring the attackers or their intentions. Here we follow Adam Shostack’s claim that attacker or asset centric threat modelling is not as effective as software centric threat modelling [Shostack].